Catching up with the wave
Notes from a month of studying AI
This February I decided to take a month off from Fiber in order to catch up with the AI wave. This is a log of what I read and watched, with notes that might help other engineers doing the same.
I didn't follow any existing curriculum. I knew that I wanted to invest one month and cover as much as I could across the entire LLM pipeline, from pre-training to optimization. [1] I ended up spending my time roughly like so:
- Week 1: Pre-training
Karpathy's lectures, 3Blue1Brown, GPT papers - Week 2: Post-training
RLHF, PPO vs. DPO, context distillation - Week 3: Scaling
Llama papers, scaling laws, CUDA, matmul - Week 4: Kitchen sink
DeepSeek and everything else I could fit
Background
It might help to start with what I knew about AI before February.
My first exposure to AI was back in High School, when I was part of a study group for AIMA. We jumped around different parts of the book for a semester and covered a bunch of search algorithms (like A* and Q-learning) and some neural networks. We even saw the basics of RL algorithms but it was outside the context of deep learning, IIRC.
The summer after freshman year of college, I took Andrew Ng's Coursera course on Deep Learning. The course was starting to become famous at the time. I also watched some of Ng's CS229 lectures (this old version here). These were a good introduction to both "traditional" machine learning (eg. SVMs) and deep learning, which was the hot new thing.
That summer I also implemented a minimalistic library for backproping in C++: https://github.com/felipap/nndl-cpp. I rediscovered it recently and I don't remember how well it works.
Later in college, I took a proper Intro to AI course, which focused on a lot of NLP. I didn't see the appeal of NLP back then. I was underwhelmed by what language models seemed capable of doing and I didn't expect them to get significantly better. (lol)
Around the same time, in 2018, I discovered Kaggle and started learning about predictive modeling. I spent a lot of time playing with XGBoost and doing feature engineering with pandas. It felt magical to train models to find patterns in data and learn to predict the future.
I graduated college in May 2020 and decided to go work with AI. I started a little data science shop to sell predictive analytics to retailers, usually e-commerce companies trying to understand which of their customers would churn. I ran that for 9 months, and learned a lot about the best practices and traps of using machine learning in production.
These experiences helped me follow the conversation around AI these past couple of years, but my understanding was still superficial. I felt the strongest need to catch up with everything I had missed since 2020.
Week 1: Pre-training
I began the month by watching Karpathy's video "Deep Dive into LLMs like ChatGPT", which had just come out a couple days earlier. This is a longer, updated version of another introduction he did in late 2023, which I decided to watch second.


I like to start diving into new subjects with a view from the top. Knowing the landscape of a field helps me connect the dots later, when I'm deep into the material. Karpathy's deep dives are perfect for this. In just a couple hours, he walks us through the entire pipeline of coding and training a conversational LLM.
Another great introduction to AI is a series by 3Blue1Brown called Deep Learning:
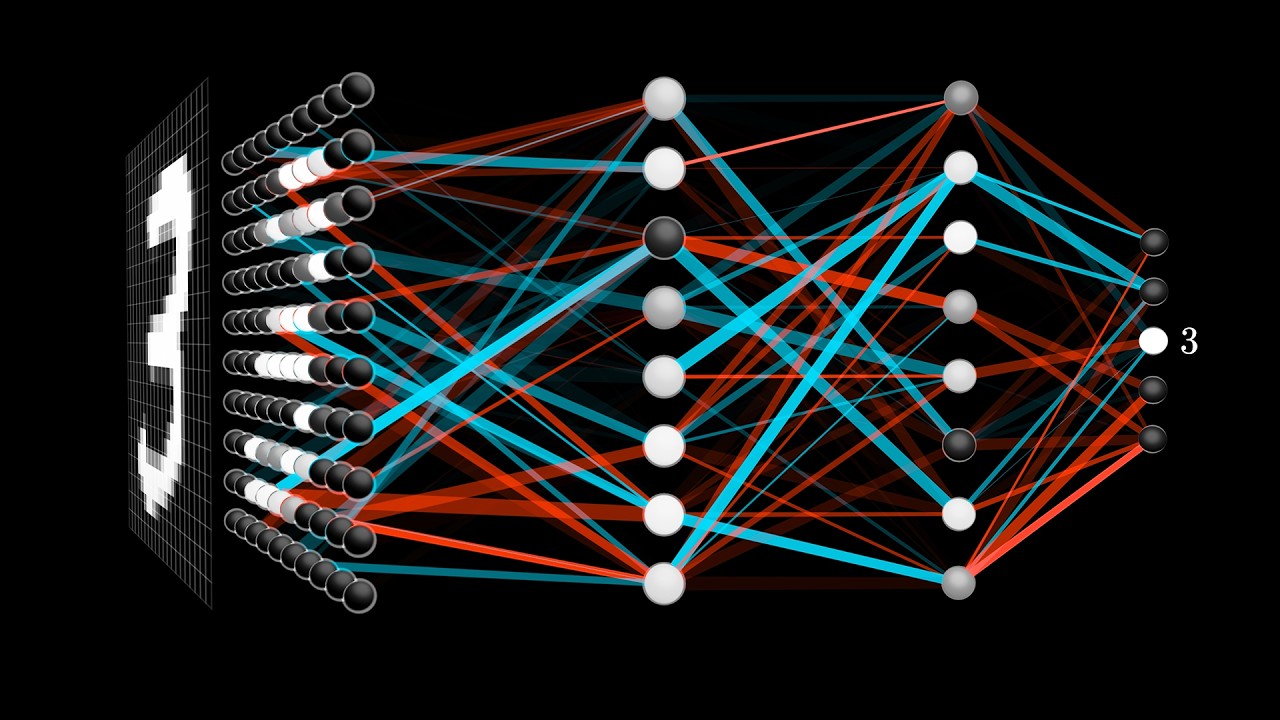
The first video of this series came out in 2017, years before the LLM boom. Back then, "Deep Learning" was the go-to term for the AI frontier. I had already seen most of these videos over the years but I wanted a refresher, so I rewatched them after Karpathy's deep dives.
I highly recommend Chapters 6 and 7, which explain the mechanisms behind the attention head and the MLP block within the transformer. Chapter 6 was what finally gave me an intuition for how QKV works. In fact, I kept coming back to these videos for the rest of the month.
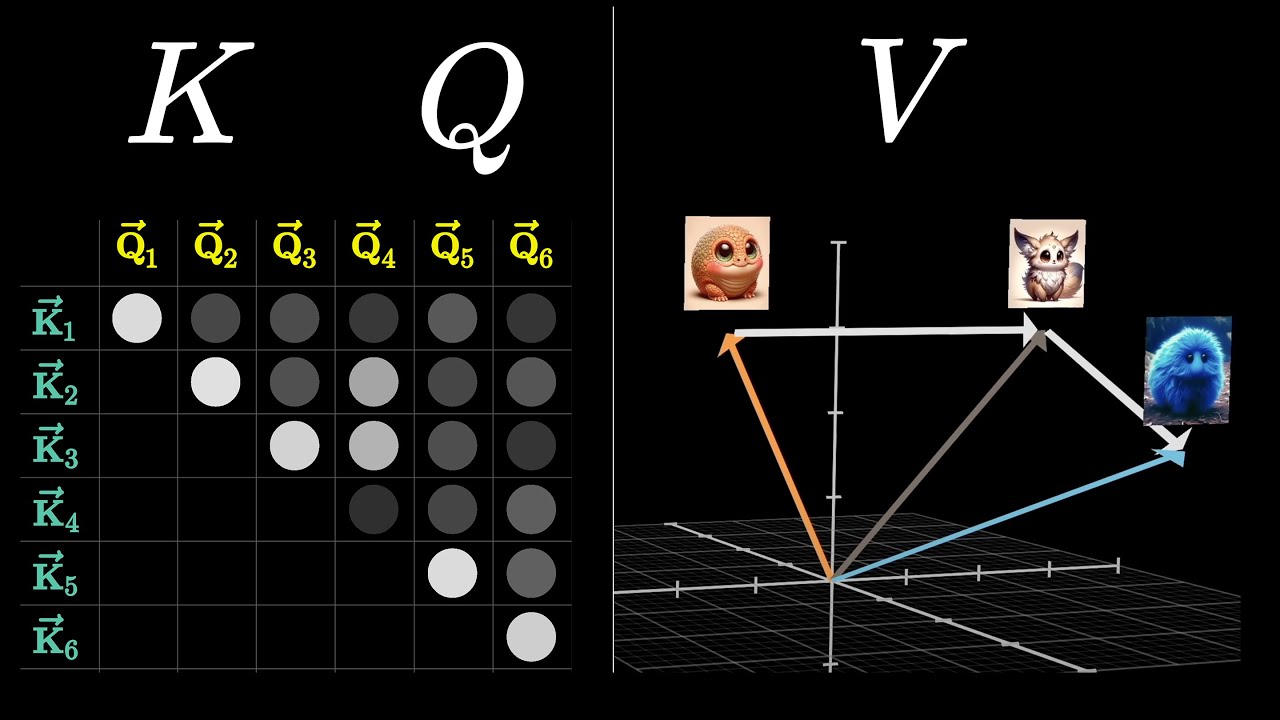
Zero to Hero
After the intros, I moved on to Zero To Hero. This is Karpathy's course on building and training a GPT-2 model from scratch.
Each video runs 2-3 hours long, but some took me a full day of work, between lesson and exercises. I watched most videos twice: first to follow along every step, and the second time to solidify what I had learned and check my understanding.
This is probably the best course on LLMs on YouTube and the best way to use it is to code along with Karpathy and do the exercises as they come. I used a Google Colab notebook and forced myself to type every line of code, instead of copying from the GitHub repo.
In terms of prerequisites, you'll need a basic grasp of linear algebra and neural networks. I found Karpathy moves very fast through the basics. Even for backpropagation, which is the topic of the first video, you'll be much better off having seen it implemented before.



My takeaway from part 3 is that deep neural networks rarely learn well on their own. They need a lot of supervision and steering. Even with good data and an optimal architecture, a lot can go wrong during training and cause deep networks to stop learning (example). Researchers have found different solutions to this problem, such as batch norm, ELUs, Kaiming initialization etc, which are covered in this lecture.

Part 4 returns to backpropagation and we're asked to do the backward pass operations by hand. Most of the lesson was exercises, which took me a long time to get through.
I found Karpathy's explanation of the backprop code a bit shallow, so I decided to derive the math myself. So I spent a long time trying to retrofit what I remembered from matrix calculus to rigorously arrive at Karpathy's solutions. But I couldn't make it work.
Much of the difficulty of part 4 stems from "broadcasting". These are rules around how we do operations between tensors when they have different shapes. I eventually learned, with the help of chatGPT, that broadcasting isn't covered by matrix calculus at all. It's just an implementation detail (of numpy, PyTorch etc).
This realization was a big unlock for me. It means that most of the operations on the high-dimensional tensors are still element-wise or matrix-wise operations. The extra dimensions are there only to help us train on multiple nodes and examples at the same time. So the code isn't as complicated as it may look.




The last video focuses on training efficiency and model performance. Karpathy shows us how to take the previous GPT model and train it to be as good as GPT-2. He uses several optimization techniques and leaves the model training on real GPUs for several hours. I wasn't in the mood to wait that long, so I just watched this one.
Attention + GPT papers
After Zero To Hero, I was curious to see how far I could get with the GPT papers from OpenAI. First I read Attention, the 2017 paper that described the transformer:
Then I read the GPT-1 paper:
At this point I looked for resources to supplement my understanding of residual networks. I was having a hard time understanding why they work. This is the best video I found:
Professor BryceResidual Networks and Skip Connections (DL 15)Then I read GPT-2:
then GPT-3, which is a scaled-up version of GPT-2:
End of week one
This was it for week one. It lasted 9 days, from a Friday to Sunday. I covered much of what I wanted to learn about the pre-training phase. On the last day I was able to open a Google Colab and rewrite 95% of the GPT code from memory, which felt great. ✌️
Week 2: Post-training
Next I sought to understand the post-training phase. I was feeling cocky after blowing past the GPT papers so I jumped to read an important RL paper next: Fine Tuning Models from Human Preferences. This was the first work published by OpenAI that applied Reinforcement Learning from Human Feedback (RLHF) to improving a language model (eg. to make it safe):
This paper really stumped me. I tried hard to read it but didn't have the necessary foundation. So I had to change course.



Being very confused by RLHF
First I backtracked to an earlier paper, which applied RLHF to Atari games. I also tried reading the paper that describes PPO, the algorithm most commonly used by OpenAI for RLHF. I spent the next couple of days bouncing between these three papers.
Proximal Policy Optimization (PPO) was designed at OpenAI in 2017 and eventually became the industry standard to RLHF language models (at least until DeepSeek's GRPO came along). The best source I found on PPO was Spinning Up. Part 3 was particularly helpful for understanding the math.
The rest of the learning came from YouTube. It's impressive how much high-quality material on AI you can find there! The clearest and most complete video I found on PPO was the following, from Umar Jamil. He goes over many of the equations from Spinning Up:

At this point, I still couldn't make complete sense of the 2019 RLHF paper. I felt like the paper glossed over all the important implementation details. So I turned to code for help.
Code for the paper had been published to the OpenAI GitHub, and I decided to use it to fill in the gaps. I spent the better part of a day just trying to get the code running on Google Colab, with little luck. The main issue was that it had been written in TensorFlow 1.0, which isn't compatible with the modern versions of Python supported by Colab. I tried running it locally but also ran into issues.
Compared to PyTorch, TF 1.0 feels hard to write and nearly impossible to read. The worst thing about it (and the cause for all the hate) is that functions exist only to build computational graphs. That means you can't debug TF 1.0 using print statements, because the real work doesn't happen when the function executes.
I tried painstakingly updating the repo code to use newer versions of TensorFlow, but it was too complicated. I hit too many issues I didn't understand, so I gave up.
What finally helped me understand the 2019 RLHF paper was this article by the Hugging Face team:

Another incredible resource is the TRL implementation of PPOTrainer:
Other helpful links
Some other videos that helped me learn RL, from the dozens I tried:
- [CW Paper-Club] Fine-Tuning Language Models from Human Preferences 🇧🇷
- Karpathy – Deep RL Bootcamp Lecture 4B Policy Gradients Revisited
- Edan Meyer - Proximal Policy Optimization Explained
- John Schulman – Deep RL Bootcamp Lecture 6: Nuts and Bolts of Deep RL Experimentation
- John Schulman - Reinforcement Learning from Human Feedback: Progress and Challenges
- Pieter Abbeel – L4 TRPO and PPO (Foundations of Deep RL Series)
- Interconnects AIHow language model post-training is done today
At one point I was very confused by why in PPO the policy and the value models tend to be two heads over the same network. I couldn't find an answer anywhere except this Reddit post.
Fine-tuning
My studies so far had unlocked other important papers on fine-tuning LLMs, including instructGPT, which is a version of GPT-3 fine-tuned for helpfulness/harmlessness:
and a paper on RLHF for summarization tasks:
Next I read Constitutional AI, perhaps my favorite paper I read this entire month:
Finally, I decided to learn about Direct Preference Optimization (DPO). I read somewhere that DPO was gaining ground as an alternative to PPO because it was easier to implement and train.
But I skipped most of the paper.

Note I left on the DPO PDF
Again on DPO, Umar Jamil's channel was very helpful:

End of week two
I wrapped up the week with this CS229 guest lecture by Yann Dubois, which has some good explainers on everything I had seen so far. It also introduced me to a lot of what I'd see in week 3; I highly recommend it.

I like the moment at 1:27:30 when a student asks "why didn't we start with PPO instead of going straight to DPO?" and the answer is "idk".
Week 3: Scaling
Two weeks in, I wanted to keep pushing toward state-of-the-art models. First I tried reading the GPT-4 technical report but didn't like it much. The paper is heavy on benchmarks and light on implementation details. So I pivoted to open-source models, starting with Llama.
LLaMAs 🦙
The Llama 1 and 2 papers were published in 2023. I noticed a clear shift in their focus compared to GPT-3. The concern with viability ("can we train LLMs to be generally intelligent?") gave way to a concern with efficiency ("how can we train the smartest model with the least amount of data/compute?"). This is clear from all the tweaks that Llama 1, and especially Llama 2, made to the original transformer, and to the post-training of instructGPT. As I read the papers, I took time to study these modifications, as I list below:
Llama 2 introduces a technique called "Ghost Attention" (GAtt), which was used during post-training to help models remember instructions over lengthy dialogues. The paper's explanation of GAtt is unnecessarily short and left me with many questions. But I found very little information online. The only article I can recommend is: LLaMA-2 from the Ground Up.
Another change I studied from Llama 2 was replacing the masked Multi-Head Attention (MHA) of GPT with the more efficient Grouped-Query Attention (GQA). In GQA, each attention head shares key and value vectors with at least one other head. This reduces the memory requirements and makes it possible to train larger models. (Or did it make it easier to shard compute? I don't remember.)
There is also MQA, a more extreme version of GQA where keys and values are shared across all heads. I read the papers for both:
I liked this explainer on MHA vs GQA vs MQA:

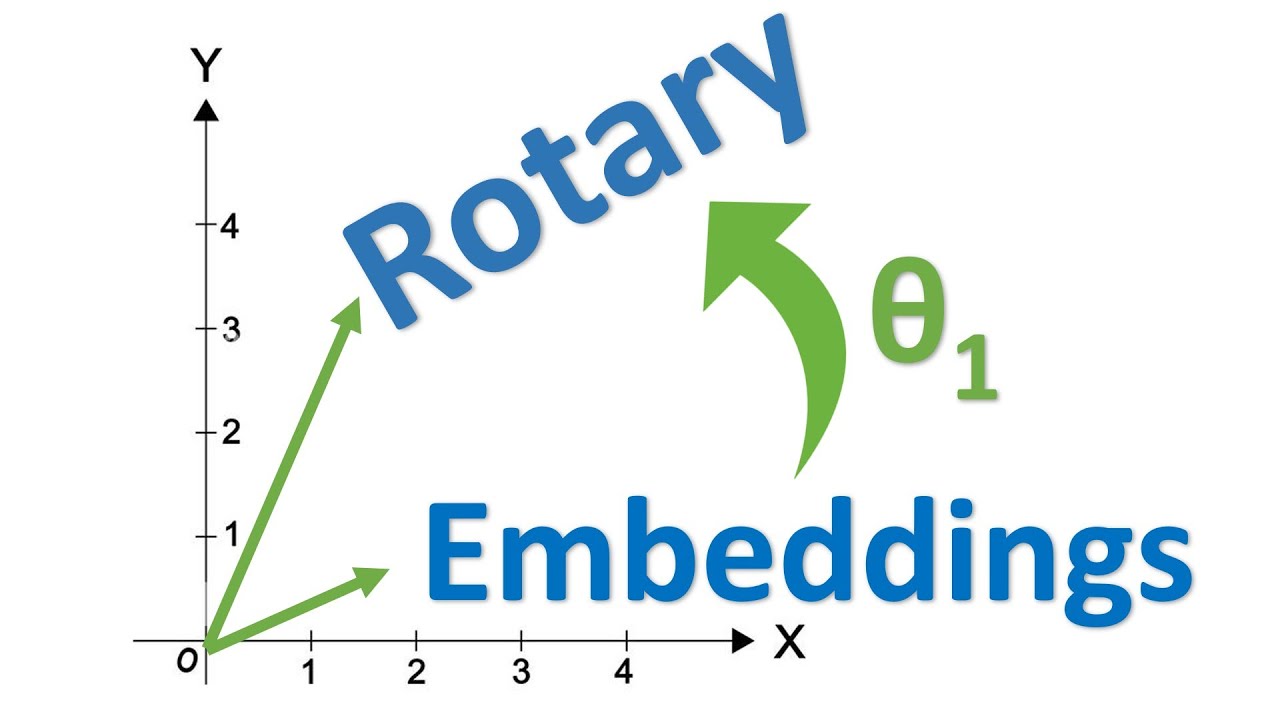
I also studied context extension. The Llama authors wanted to extend the context window for inference without degrading the model's performance (see needle in a haystack). One solution they used was Rotary Position Embeddings (RoPE). They make it easier for nodes in the attention heads to understand their relative position to other nodes, rather than learning based on absolute positions.
I skimmed the RoPE paper below but decided that the math would take too long to understand. So I turned to YouTube instead. Links are below.

![How Rotary Position Embedding Supercharges Modern LLMs [RoPE]](https://img.youtube.com/vi/SMBkImDWOyQ/maxresdefault.jpg)
I also read this earlier paper on encoding relative positions:
Overall, the Llama 2 paper is long but worth the read. They made a bunch of other changes which I didn't have time to go into. I recommend this survey video by Umar Jamil:

Scaling laws
The Llama papers introduced me to scaling laws, which I had heard of but never really understood. I decided to read two seminal papers:
This Wikipedia page is also great:

Scaling laws are more about the economics of AI than the computer science of AI. They explain the billion-dollar bets that tech companies were making in 2022-2024. They gave CEOs the confidence to spend on compute, "knowing" that they'd see returns to intelligence. Glad I took some time to dig into this.
Mistral
Next, I read two papers by the Mistral team: Mistral 7B and Mixtral of Experts.
Mixtral popularized the use of "mixture of experts" ensembles inside of LLMs, which we now see in many state-of-the-art models.
Llama 3 → Infra → CUDA
Llama 3 came out in July 2024 and continued the march towards efficiency and better post-training techniques. (The paper has a whopping 200+ contributors, and hundreds of others get partial credit. You can really feel the weight of a trillion-dollar company behind it.)
Sections 3.3 and 6 cover infrastructure for training and inference, which were entirely new to me. They sent me down a rabbit hole of GPUs, CUDA, optimization etc. But my descent down the hole was a bit disorganized.
Back in the first week, I had spent some time watching Geohotz live-code the early versions of tinygrad, which is like a smaller version of PyTorch. In those videos Geohotz wrote some kernels for matrix operations using OpenCL, which I hadn't seen before. That was my first exposure to GPU programming.
Now in week three, I went back to CUDA to learn more about optimizing LLMs for training and inference. This is probably one of the first videos I watched, and where I'd also recommend you to start:

This blog post on PyTorch internals was praised by lots of people online:

The best way to learn about how efficient matrix multiplications are implemented in GPUs is this blog post by Simon Boehm. His entire blog is worth a read but I'd start here:
I wanted some hands-on experience in CUDA to solidify my understanding. I used a Google Colab notebook with PyCuda to implement the algorithms from Boehm's post. I also used PyCuda on Colab to try out different kernels for image processing. (The conventions and nomenclature around GPU programming made a lot more sense once I applied it to a graphics problem.)
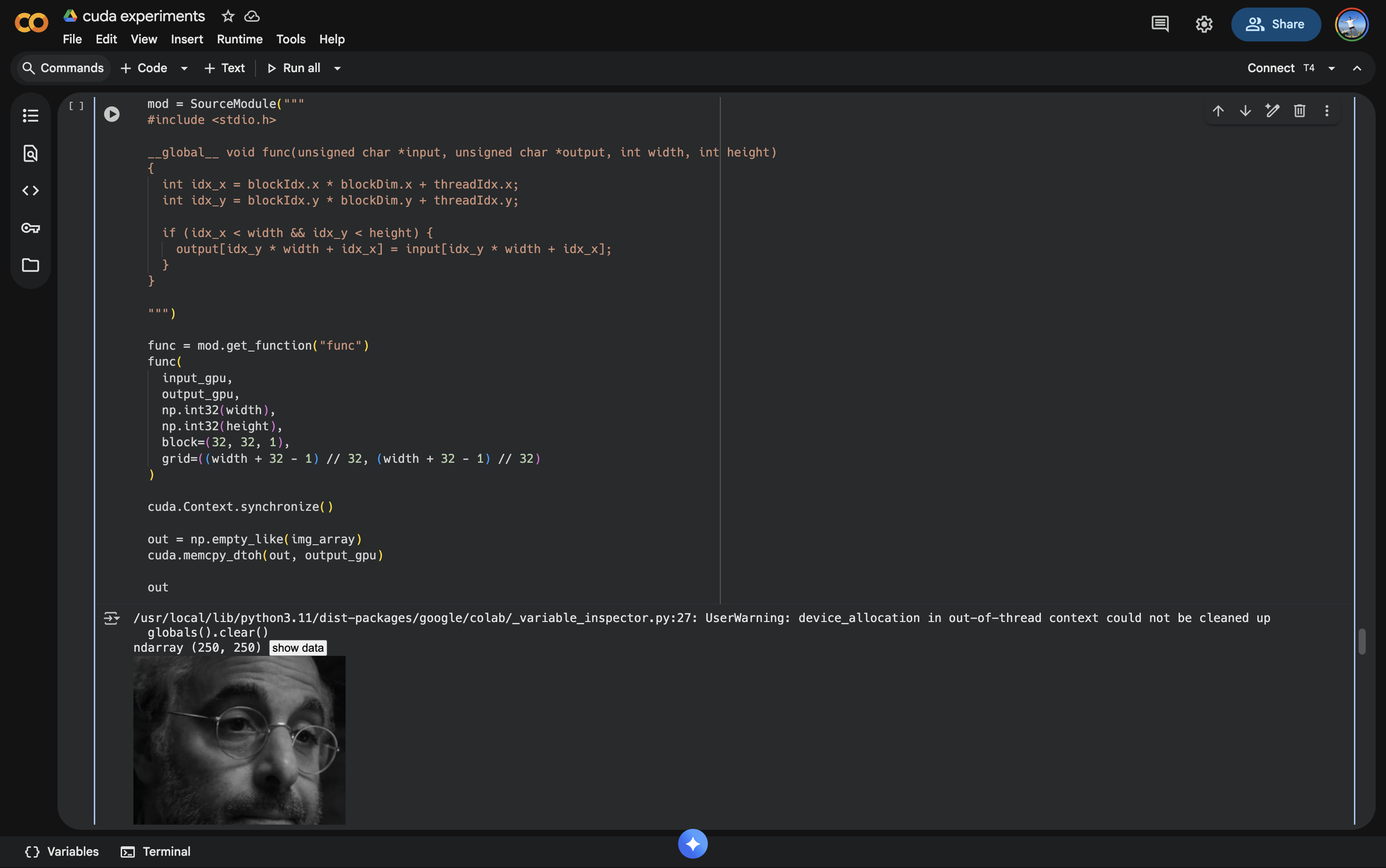
Using CUDA to turn Stanley Tucci black and white lol
I bounced between a bunch of other videos. The next great resource I found was the Ultrascale Playbook, which had just come out days earlier.
Here's a walkthrough with one of the authors, Nouamane Tazi:

End of week 3
Week three ended with lots of open threads to dig into. I was running out of time.
Week 4: Kitchen sink
At some point in the first couple of weeks I set myself the target of being able to read — and understand — the recent DeepSeek r1 paper by the end of the month. r1 was released mid-January and for a couple weeks it was all anyone talked about on Twitter. So that's where I went next.
DeepSeek
r1 is a conversational model like chatGPT, but built on DeepSeek v3, a base model released in late 2024. I decided to read both papers, starting with r1:
r1 is cool but v3 is even cooler. The v3 paper goes into meticulous detail about model architecture, training infrastructure, optimization etc. It's a level of transparency I never saw in the papers from American labs.
One of the key contributions from DeepSeek was replacing PPO with a new implementation of RL called Group-Relative Policy Optimization (GRPO). DeepSeek published GRPO a year ago, in a paper that I decided to skip. But I watched parts of this explained by Yannic:
![[GRPO Explained] DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://img.youtube.com/vi/bAWV_yrqx4w/maxresdefault.jpg)
In the v3 paper, I had a hard time with the topic of quantization. I thought I understood FP8 after reading the Llama 3 paper, then I noticed some gaps in my knowledge. I watched a bunch of videos but this one from Umar Jamil is the best introduction I found:

I watched a bunch of other breakdowns of r1 and v3, including:
- Deep Learning with YacineDeepSeek R1 Theory Overview | GRPO + RL + SFT
- Sasha RushHow DeepSeek Changes the LLM Story
- Gabriel MongarasDeepSeek-V3
Everything else
The rest of the week was a mishmash of lots of different topics. I had a list of outstanding questions I wanted to answer before the month was over. Things like: What is LoRA? What is prefix tuning? How does Flash Attention v2 work?. I set off to tackle as many of these as I could.
Here's some of what I read and watched:



For months I kept hearing about inference-time compute but never really understood what it meant. So I decided to read the original papers on chain-of-thought:
I also read the original RAG paper. (Did you know it does backpropagation through to the embedding model?)

I really enjoyed this interview with Tim Dettmers, who's a big name in open-source and optimization:

And to close the month, one of the last videos I watched was this talk by Karpathy, explaining his latest project llm.c:

Final thoughts
I'm happy with how the month turned out. I managed to cover a lot in these four weeks, and have a much better understanding of AI today.
I wish I had done this sooner, but that would've been hard given my responsibilities at Fiber. The product wasn't stable enough to leave it running in the background for existing customers. I spent a lot of my time last year just building.
It would've been hard to study this part-time; there's too much to learn. I probably spent 80-100 hours per week on this project, between papers, lessons and homework.
I used a massive Notion document to keep track of everything I did that month. The document was the basis for this blog post. I logged every piece of content I watched and every question I struggled with. I recommend everyone else do the same; it's very useful to be able to revisit links later.
Of course, there's so much material that I didn't have time to cover. There were about 30 papers and 20 other resources that I was hoping to get to, but ran out of time. And there are whole topics within AI that I had to skip eg. interpretability.
Next, I want to spent some time on "AI engineering", the application of LLMs to build smart products. It's the part of the stack that interests me the most.
Notes
- I considered using this, which is supposed to be a list of papers that Ilya Sutskever recommended to John Carmack to understand the state-of-the-art in AI. There are multiple versions of this list online but I couldn't verify the authenticity of any of them.
Website updated March 2026