A month of AI
Notes from catching up with the wave
This February, I put Fiber in maintenance mode to catch up with the AI wave. This is a log of what I read and watched, with notes that might help other engineers doing the same.
I didn't set out with a particular curriculum. I knew I wanted to spent a month and cover the basics across the entire stack, from algorithms to implementation. In retrospect, I spent my time roughly like so:
- Week 1: Pre-training
Karpathy's lectures, 3Blue1Brown, GPT papers - Week 2: Post-training
RLHF, PPO vs. DPO, context distillation - Week 3: Scaling
Llama papers, scaling laws, components - Week 4: The kitchen sink
CUDA, matmul, DeepSeek, and everything else I could fit
Background
It might be relevant to mention what I knew about AI before
It might be relevant to mention what I knew about AI before this month started. I had a decent foundation in ML, for a software engineer. My first exposure was back in High School, when I went through the AIMA textbook with a group of friends. Then in college, I spent summer after freshman year going through Andrew Ng's classes on Coursera and CS229 (this course). I later also took intro to AI course.
Late 2018, I learned about Kaggle and tried my hand at prediction modeling. (Ironically, I used to find NLP boring back then.)
Some other resources I remember using which might still be worth it:
- Neural Networks and Deep Learning by Michael Nielsen
- The Deep Learning textbook by Goodfellow, Bengio and Courville
Before this month, I was mostly "caught up" to the 2019 state-of-the-art in AI. But lot had happened since...
Week 1: Pre-training
I started week one watching Karpathy's "Deep Dive into LLMs like ChatGPT", which he had just released a couple days earlier. It's a newer, longer version of another introduction he did in late 2023, which I watched second.


When I'm diving into a new subject, I like to start with a view from the top. Knowing the landscape ahead of time helps me connect the dots later, when I'm going through the details. [2] Karpathy's deep dives are perfect for this. In a couple hours, he walks you through the entire pipeline of designing, training and refining a conversational LLM.
Another fantastic introduction to LLMs is 3Blue1Brown's series on Deep Learning:
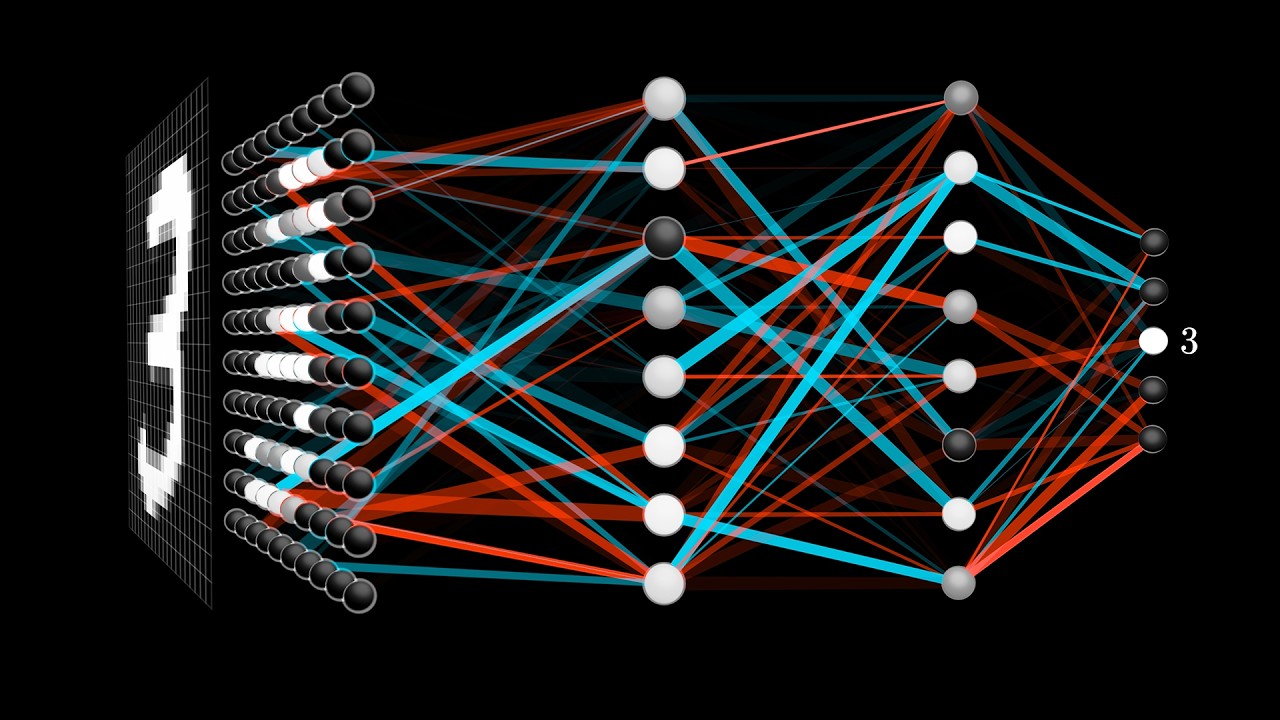
These videos give you the best intuition for how and why LLMs work. I had already watched a handful of them over the years but I could use a refresher, so I decided to rewatch the series after the deep dives.
One video stood out, Grant's explanation of the attention mechanism inside transformers. This was the first time that QKV clicked for me, and I kept coming back to these videos for the rest of the month.
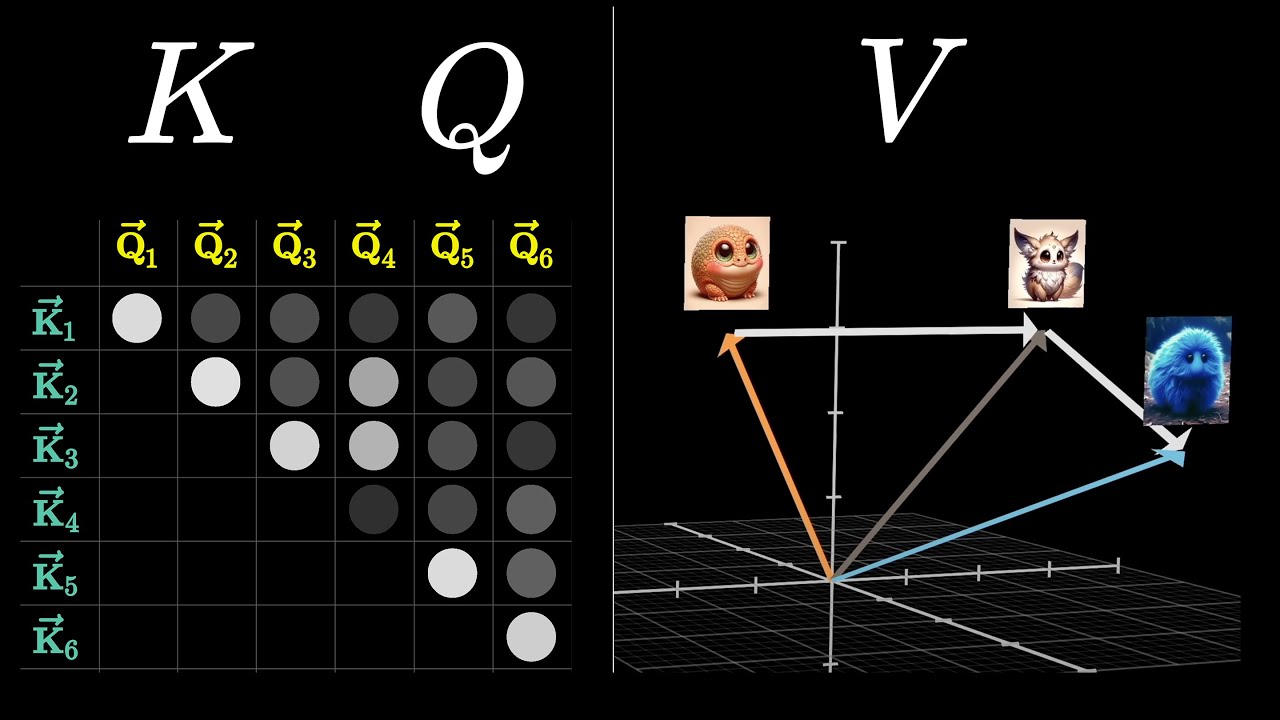
After 3Blue1Brown and the deep dives, I moved on to Zero To Hero.
Zero to Hero
This is the course by Karpathy that takes you through building and training a model like GPT-2 from scratch.
Each video in the series is 2-3 hours long, but some took me a whole day of work, between lesson and homework. I watched most videos twice: the first time to follow along carefully, and the second time to cement the content and catch anything I might've missed.
The best way to learn is to code along with Karpathy and do the exercises as they come. I used a Google Colab notebook and forced myself to type every bit of code, instead of copying from the GitHub. [3]
In terms of prerequisites, you'll want a basic grasp of linear algebra and neural networks before diving in. Karpathy does not cover linear algebra, not even a bit. And even back backprop, which is a topic of the first video, you're better off having seen it implemented before.



The gist of part 3 is that neural networks don't just learn by themselves, typically. Even with good data and a good architecture, a lot can happen during training that causes them to get stuck in local maxima, or to stop learning entirely. Researchers have developed many solutions to this over the years, including batch norm, ELU, Kaiming etc, which are the subject of this lesson.

Part 4 returns to the topic of backprop and asks us to do the backward pass by hand. Most of the lesson is exercises, which took hours to do.
I found Karpathy's explanation of the backprop code a bit "hand-wavy" and I wanted to derive the math myself. Instead of consulting the internet, I spent hours trying to retrofit what I remembered from matrix calculus to more rigorously explain what Karpathy was doing. But I couldn't make it work.
Much of the difficulty of part 4 stems from "broadcasting", which are rules around how we do operations between tensors of different shapes. I eventually learned, with the help of ChatGPT that broadcasting is not covered by matrix calculus. It's just an implementation detail.
This was a big unlock in my understanding. It means that most of the operations we do with high-dimensional tensors are still element-wise or matrix-wise operations. The extra dimensions are there only to help us train on multiple nodes and examples at the same time.



Finally, the last video of the series is Let's reproduce GPT-2. It's a lot like the GPT one, but Karpathy uses GPUs and leaves the model training for several hours. I wasn't in the mood to wait that long so I ended up just watching along. The video is 4-hours long and has some implementation details that I haven't seen documented anywhere else on the internet.

Attention + GPT papers
After Zero to Hero, I was curious to see how far I could get into the GPT papers. First I read Attention, the 2017 paper that introduced the Transformer architecture:
Then I read the first GPT paper
I had to use YouTube to supplement my understanding of residual networks. I knew what they were because of Karpathy, but I didn't have an intuition for why they worked. This was the best video I found: Professor BryceResidual Networks and Skip Connections (DL 15)
Then I read GPT-2
then GPT-3, which is essentially a scaled-up version of GPT-2:
What's special about GPT-3 is that it's the first LLM trained on a general-purpose dataset that is able to perform a wide range of tasks better than fine-tuned specifically for those tasks.
End of week one
And this was it for week one. In retrospect, I covered most of what I wanted to learn about pre-training. The "week" actually lasted 9 days, ending on a Sunday. On the last day I was able to go back to Colab and rewrite the entire GPT-1 from scratch from memory, which felt great. ✌️
Week 2: Post-training
Next, I wanted to understand the post-training phase, which isn't covered in the Zero to Hero series. I felt a bit cocky after making it through the GPT papers, so I next tried to read Fine Tuning Models from Human Preferences. This was the first work released by OpenAI which applied Reinforcement Learning From Human Feedback (RLHF) to improving a language model.
The paper stumped me. I tried hard but didn't have the foundation to understand it.



Being very confused by RLHF
So I backtracked to an earlier work, which applied RLHF to Atari games, and to the DPO paper from 2017, which describes the RL algorithm most used by OpenAI. I spent the next few days bouncing between these three papers, still confused.
Learning PPO
Proximal Policy Optimization (PPO) is an RL algorithm published in 2017 which became the industry standard for fine-tuning LLMs (at least until DeepSeek's GRPO came along). The best resource I found on PPO was Spinning Up, an old website put together by Josh Achiam at OpenAI, which covers all things RL. Part 3, in particular, was very important for the math.
Other than Spinning Up, I did most of my learning on YouTube. It's impressive how much good content you can find there. The best explanation I found of PPO was probably from Umar Jamil. He goes over many of the equations from Spinning Up.

Wrestling with code
Even after learning PPO, I still couldn't make sense of the 2019 fine-tuning paper. I felt the paper glossed over all the important details, so I turned to the code for help.
The code for the paper was available on OpenAI's GitHub, so I decided to use it to fill in the gaps. I spent a whole day just trying to get it running on Google Colab, with little luck. To start, the data used in the study had vanished from the web sometime since 2019. Worse, the code was written in TensorFlow 1.0, which isn't compatible with the recent versions of Python supported by Colab.
I tried painstakingly updating the code to run with newer versions of TensorFlow, to no avail. Compared to PyTorch, TF 1.0 is hard to write, hard to debug, and nearly impossible to read. The worst part about 1.0 (and perhaps the reason why everybody hates it) is that functions exist only to build computational graphs. That means you can't debug using print statements or step through code with a debugger, because the real computation (eg. computing an activation layer) doesn't happen when the function is executed. So nothing means what it looks like it means. [4]
What finally helped me understand the paper was this article by the Hugging Face team.

I kicked myself for not Googling more and finding this sooner. It would've saved me a couple days of work.
While I couldn't get far on lm-human-preferences, I was able to learn a lot about PPO reading the TRL implementation of PPOTrainer:
I wish I had found this straight away.
Some other resources that were helpful to learn RLHF (out of many dozens I tried):
- [CW Paper-Club] Fine-Tuning Language Models from Human Preferences 🇧🇷
- Karpathy – Deep RL Bootcamp Lecture 4B Policy Gradients Revisited
- Edan Meyer - Proximal Policy Optimization Explained
- John Schulman – Deep RL Bootcamp Lecture 6: Nuts and Bolts of Deep RL Experimentation
- John Schulman - Reinforcement Learning from Human Feedback: Progress and Challenges
- Pieter Abbeel – L4 TRPO and PPO (Foundations of Deep RL Series)
At one point I was also very confused by why in PPO the policy and the value models tend to be two heads over the same network. I couldn't find an answer anywhere except this particular post on Reddit.
Fine-tuning
Understanding RLHF via PPO unlocked other important papers on fine-tuning LLMs, including instructGPT (a fine-tuned version of GPT-3):
Then I read Constitutional AI, perhaps my favorite paper I read this entire month:
End of week two
Finally, I decided to learn about Direct Preference Optimization (DPO). I had read somewhere it DPO was quickly gaining ground as an alternative to PPO that was easier to implement and more stable to train.
So I read some of the paper:

Note I found on the DPO PDF
And again Umar Jamil's channel was very helpful:

I ended the week with this CS229 guest lecture by Yann Dubois, which has some good explanations on PPO and DPO.

There's a moment at 1:27:30 which validated me. Student asks why they didn't start with DPO. The systems section of the lecture also a good foreshadow to what was to come in week 3...
Week 3: Scaling
- Halfway mark
- Needed to keep pushing myself closer to the state-of-the-art models
- Tried reading the GPT-4 paper but saw after a skim that it was heavy on the benchmarks but light on the implementation details
- Decided to read open-source papers instead, specifically on Meta's Llama and Mistral
- All released in 2023 and quite transparent on the details
- Llama 2 invented a technique called Ghost Attention (GAtt), which they used during RLHF to make the model adhere to instructions even in long dialogue
- Their explanation of GAtt is short and left me with lots of questions
- I found virtually zero explainers online, across YouTube or technical forums
- The only resource I found was this: https://cameronrwolfe.substack.com/p/llama-2-from-the-ground-up
...
- Then I read the Mistral papers, which introduced me to concepts like Mixture of Experts and context extension, which I will touch on below
Components
- GPT 1 through 3 were mostly the same architecture trained on different scales
- Back then researchers were concerned with showing that models could become "intelligent"
- In 2023 we started to see mass adoption of AI, following the release of chatGPT in November 2022
- Labs shifted their focus to training and deploying models at scale
- They started to tweak individual components of the transformer trying to squeeze more performance and efficiency
...
- For example, Llama 2 replaces the autoregressive Multi-Head Attention (MHA) of GPT with a Grouped-Query Attention (GQA), which reduces the memory requirements making it easier to train larger models. In GQA, each head generates a unique query vector, but they share the key and value vectors with one or more other heads. (I was surprised at first to find that this works well, though I guess it makes sense that models would learn to adapt to this.)
- There is also MQA, a more extreme version of GQA in each values and queries are shared across all heads. Only the queries are unique.
- MQA was formulated by Noam Shazeer in 2019.
- Another concern was how to offer large context windows for inference without deteriorating performance (needle in a haystack etc)
- One solution to context extension is Rotary Position Embeddings (RoPE), used by Llama 1 and 2.
- RoPE helps nodes understand their relative distance to one another, instead of relying on absolute positions.
- I gave the RoPE paper a shot but realized the Math was going to take long so I fell back on YouTube instead. I was mostly interested in the general intuition.
- These are the YouTube explained I liked:
![How Rotary Position Embedding Supercharges Modern LLMs [RoPE]](https://img.youtube.com/vi/SMBkImDWOyQ/maxresdefault.jpg)
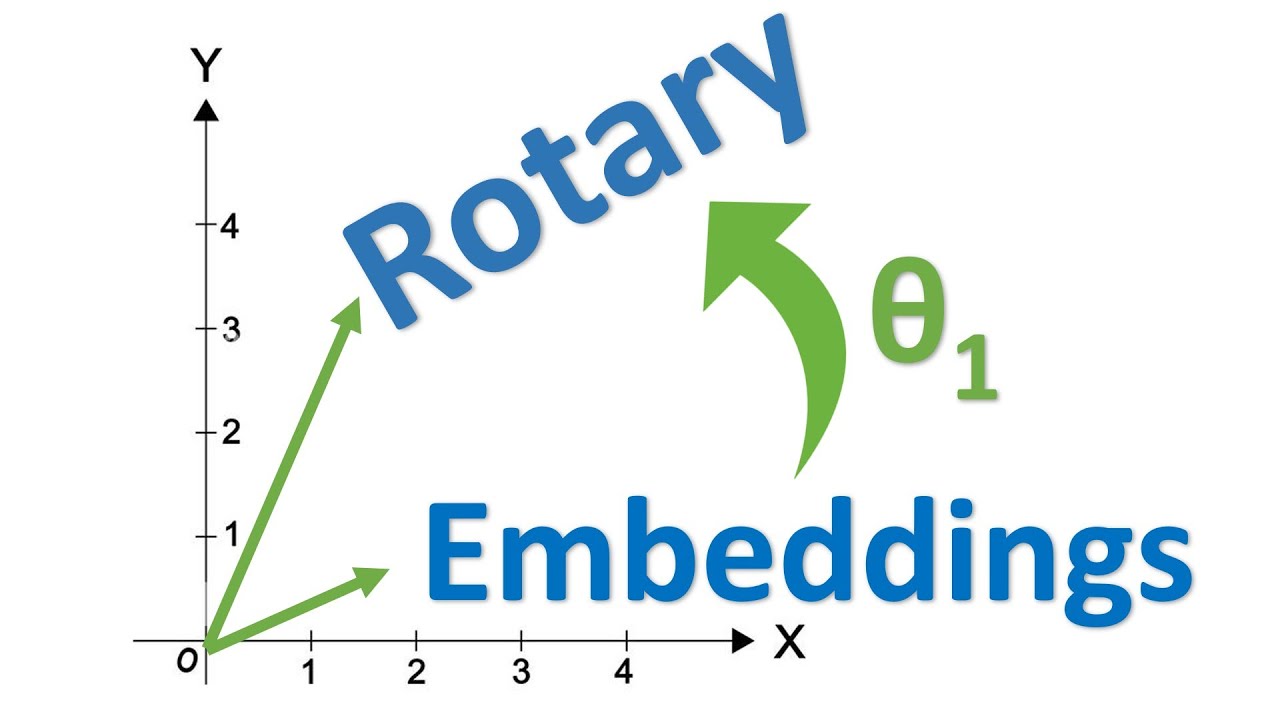
- I did read an earlier paper on relative position representations, though I don't remember why. :)
- Llama and Mistral make several other tweaks to GPT but I didn't go deep into them.
- Umar Jamil has a great explainer on Llama, which covers many of these tweaks and that I highly recommend:

Scaling laws
- Another concern of researchers by 2023 is how big to make the models and how long to train them for.
and Chinchilla:
I also liked the Wikipedia page on Neural Scaling quite thorough:
Llama 3
- Llama 3 was released in July 2024
- Clear signs of professionalization. It lists a whopping 235 core contributors, and many hundreds more get partial credit. You can feel the weight of $1T Facebook behind it.
DeepSeek r1 and v3
- Somewhere along the first couple of weeks I had set myself the goal of being able to read and understand the DeepSeek r1 paper. So I wanted to do that.
- DeepSeek made noise with r1 but in a way the innovation is secondary compared to the base model in which r1 is built, called DeepSeek v3.
DeepSeek r1 pioneered GRPO, which is like PPO but simpler to implement.
Wrapping up
Compared to the first couple weeks, this was a big mess. I'm not sure what I read and in what order.
Week 4: The kitchen sink
With the month coming to an end, I started rushing to cover as much ground as I could. My first goal was to understand DeepSeek r1 and why it was a big deal.
Going low

With this knowledge, I was able to follow along with the Ultrascale Playbook, which had recently come out:
Application
Finally I wanted to learn some application as well. It was becoming clear that my zone of genius was going to be on how to apply these LLMs, as opposed to how to make them smarter or more efficient.

I ended up reading 30 papers in 30 days.
My plan for week 4 was to learn "AI engineering". That didn't happen. Not only because the subject is too broad (and most importantly right within my zone of interest), but because there were things I still wanted to learn before moving on to the top stack.
Epilogue
I had been planning to take time to study AI for a while. I'm very happy with how this month turned out. I only wish I had done it sooner.
Moving back to San Francisco in January increased my sense of urgency to catch up. AI is the only thing we talk about at work and at home. On February 5th, Karpathy dropped his "Deep Dive" video, which quickly went viral on X and HackerNews. I originally decided to take a Friday off to watch it, but it quickly became a month-long effort.
Going forward, I want to dedicate some time to AI engineering. It's a part of the puzzle that I'm still missing. Some content I'm consuming next:
https://news.ycombinator.com/item?id=43323946
Thanks Abhi and James for the feedback.
Notes
-
I recently rediscovered a barebones C++ implementation of backprop, which I wrote that summer: https://github.com/felipap/nndl-cpp. I think it works but I'm not sure.
-
Another way to put it: consume the "easy" content first.
It took me many years to learn this lesson. In my teens, my strategy for learning a subject was to find the most complete resource on it — typically a thick textbook — and begin reading it from page one. When I got stuck, I'd just go back and reread the chapter(s). I thought I was being rigorous with my education but this is by far the slowest way to learn.
Today I start with the ELI5, then the "ELI10", and so on. I look for high-level explanations then I go progressively deeper from there. When I get stuck, I look for a different resource.
For example, if I wanted to learn Scala today, I'd start by watching Fireship's Scala in 100 Seconds. Then I'd look for a good 15-30 minute introduction to the language. Then maybe a tutorial that I could follow along. Meanwhile, younger me would've jumped straight into an 11 hour course and would feel bad about abandoning it.
-
I'd go further and say that I wouldn't bother watching the series without dong the work and writing your own notebooks. The difference in how much you absorb is huge. And I found myself many times going back and consulting previous code and notes I had written.
-
If you're able to define all computation symbolically, TF can automatically
?. There is a famous list floating around which I considered using. It's a list of papers that Ilya Suskteiver supposedly recommended to John Carmack over a dinner. https://www.lesswrong.com/posts/t4ZBjAjXk2NqqAqJ7/the-27-papers There are a couple different versions of it online. As far as I could tell, these are speculations. We don't actually know what are tehse papers he recommended.